ボーン・デジタルの情報学
第6回:学術情報のアーキテクチャ、ボーン・デジタルの本質
大向一輝(国立情報学研究所准教授)2010年06月15日号

本連載では、紙を通じた情報流通からボーン・デジタルに移行し、その問題点や課題を含めていち早く体験している学術情報の世界について紹介してきた。最終回となる今回は、いまだ変化し続ける学術情報分野の現状と未来、そこから見えてくるボーン・デジタルの本質について述べていきたい。
学術情報の「アーキテクチャ」
学術情報をめぐる状況は時々刻々と変化しており、その勢いは増すばかりである。情報技術の進歩がもたらす変化もさることながら、この分野のプレイヤーとなる公共セクターや民間企業の入れ替わりの激しさもまた特筆に値する。2009年末には、世界第2位の学術出版社であるシュプリンガー(ドイツ)がスウェーデン・シンガポールの投資会社連合に数千億円規模で買収され、大きなインパクトを与えた。
これまでの連載でも、さまざまな機関が提供するサービスを紹介してきたが、どの機関がどのような種類のサービスを提供しているのかがわかりにくいとの指摘を受けた。ここでは、本連載のまとめの意味を込めて、データのあり方から見た情報アーキテクチャという観点で整理してみたい。
1次データ
学術論文本体のデータベース、アーカイブ。紙媒体からボーン・デジタルに移行中。学術雑誌の発行主体は少数の巨大出版社に集約されつつある。その一方でオープンアクセス(連載第4回で詳説)の流れもある。例:近代デジタルライブラリ(国立国会図書館)、CiNii(国立情報学研究所)の一部、J-STAGE・Journal@rchive(科学技術振興機構)、MyOpenArchiveなど。
2次データ
文献に付随するタイトル・著者情報・概要などのデータ。書誌やメタデータと呼ばれる。各種データベースに分散して存在しているデータを一元的に集め、論文検索サービスなどに用いられる。従来から専門家向けサービスで横断検索が行なわれてきたが、近年ではウェブ検索エンジンが進出している。例:CiNii・NACSIS-CAT(国立情報学研究所)、Google Scholarなど。
2.5次データ
メタデータのなかでも論文ID・著者IDや所蔵している図書館といった、文献そのものには書かれていないデータ。複数のデータベースの内容を統合する際に必要となる。IDには書籍におけるISBNのようにあらかじめ体系化されているものと、前回紹介したCiNiiの著者IDのように、事後的に生成あるいは推定しなければならないようなものがある。後者を実現するためには機械処理やユーザの参加が必要になる。
3次データ
論文間の引用関係や、それに基づく論文・著者の評価データ。大量の文献を分析することではじめて得られる情報である。引用データには引用文献索引データベース(国立情報学研究所)、Web of Science(トムソン・ロイター)、Scopus(エルゼビア)などがある。評価データには自然科学・社会科学分野における学術雑誌の影響度指標であるインパクトファクター(トムソン・ロイター)がある。引用についてはその網羅性、評価については指標が一人歩きする懸念もあるが、両者ともに強力なツールであることは間違いない。
このように、学術論文はそこに書かれている情報だけが重要なのではなく、膨大な文献が作り出す「知識の空間」における個々の論文の位置づけに関する情報、その空間自体を俯瞰することで得られる情報、新たな分野の兆候といったより高次の情報を生み出すものとして必要性がますます高まっている。このような状況にあって、1次データである学術論文データベースはもとより、2次データ・3次データを維持管理するサービスの需要も急速に拡大している。
そして、どの層においても激しい国際競争が行なわれており、それと同時に各プレイヤーによる連携が模索されている。例えば、研究者IDについてはOpen Researcher Contributor Identification Initiative(ORCID)と呼ばれる国際的な枠組みが提案され、各国の出版社や国立図書館、大学が名を連ねている。この活動が順調に進めば、近い将来にはすべての研究者がIDを持ち、論文にこのIDを記載した状態で投稿することになるものと思われる。
基盤的な方向に向かう活動としては、論文の前段階すなわち研究のプロセスのなかで作り出される生データの公開・共有が始まっている。0次データとも呼ぶべきこのような研究データは、インターネットの力によって組織を超えた大規模な共同研究のプラットフォームとして活用が進んでいる。
Eサイエンス・データサイエンス
学術論文が研究者の著作物でありながら同時にデータでもあるという世界において、研究活動そのものがどのような姿をしているのか、その先進的な例としてゲノム解析や創薬に代表される生命科学分野の例を紹介する。
医学・生命科学分野では、アメリカ政府の方針によって研究費による成果をオープンアクセスの論文アーカイブMEDLINEで公開することが義務づけられており、主要な文献に関する1次データ、2次データを容易に検索・入手することができる。また、この分野では研究対象となる物質名や分析手法などがある程度定型化されており、それらのデータベースが整備されている。
ここで、論文検索と物質データベースの情報を組み合わせると、特定の物質に対してどのような分析がなされているか、あるいはなされていないかを機械的に判別することができる。こういった作業を大量かつ自動的に行なうことで、新たな研究のターゲットをすばやく発見することが可能になる。このような技術はデータマイニングと呼ばれており、ビジネス分野で活用されてきたが、現在では学術分野でも必須の技術になりつつある。これらの技術を駆使した新たな研究の方法を、演繹的な科学、帰納的な科学、シミュレーションに続く新たな方法としてEサイエンスやデータサイエンスと呼ぶことがある。
MEDLINEのデータを対象として、病名や物質名の関係性に基づく検索機能を提供している「MEDIE」(東京大学辻井研究室)を図1に示す。
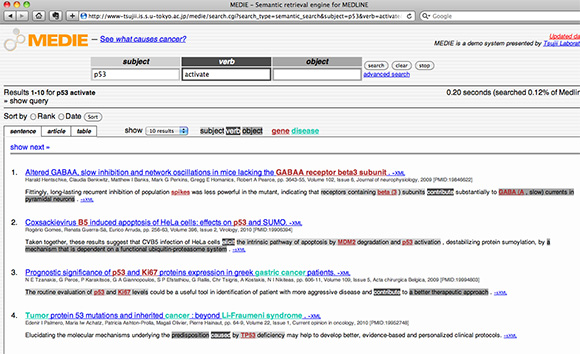
1──医学・生命科学のセマンティック検索エンジン「MEDIE」
URL=http://www-tsujii.is.s.u-tokyo.ac.jp/medie/
この先には、人間が論文が書き、人間が論文を読み理解するという従来の学術情報流通の枠組みを超え、書かれた論文はコンピュータが読むという構想がある。そのためには、コンピュータ向けのより厳密な表現と各種データベースとの密な連携が必要になるが、進展によっては論文自体のフォーマットが変わっていくことになるかもしれない。
ウェブの創始者ティム・バーナーズ=リーは、ウェブ自体をこのような概念で再定義し、これをセマンティック・ウェブと呼んでいる。セマンティック・ウェブでも、コンピュータ向けの厳密な情報の記述と辞書との連携によって検索エンジン以上の知的な自動処理を目指すとしている。
ボーン・デジタルの本質
これまで、学術分野におけるボーン・デジタルの歴史を駆け足で見てきた。情報の利用者と生産者が同じか極めて近いところにいる学術コミュニティでは、情報流通のスピードを最大限に高めるためにボーン・デジタルへの移行は必然であったといえる。
しかしながら、コピーの容易さや劣化しないというデジタル情報の利便性はあくまでも人間に向けてのものであり、表面的な特徴の一部でしかない。それよりも、情報のデジタル化はアーカイブを膨大な知識が集積された場・ネットワークに変化させ、そこから新たな知識・知見を取り出すことが可能となるというインパクトの方がはるかに影響が大きい。
その意味で、ボーン・デジタルは単なるツールの変化、メディアの変化にとどまらず、根本的な知のあり方に関する変化であるといってよい。そして、ボーン・デジタル時代のアーカイブは知識をただ蓄積するだけではなく、知識が生まれる場として生まれ変わらなければならない。
これが、学術情報分野がいち早く経験し、書籍や音楽、映像などあらゆるメディアがこれから経験することになる「いつか来る道」の姿である。


